

As entrepreneurs and AI strategists, I’ve witnessed countless “game-changing” AI releases in last few months. But sitting in my office at 3 AM, watching Kimi K2 Thinking autonomously orchestrating complex workflows across 200+ tool calls, I realized something fundamental had shifted. This wasn’t just another incremental improvement, it was the moment open-source AI caught up to the proprietary frontier.
What is a “Kimi K2 Thinking” model?
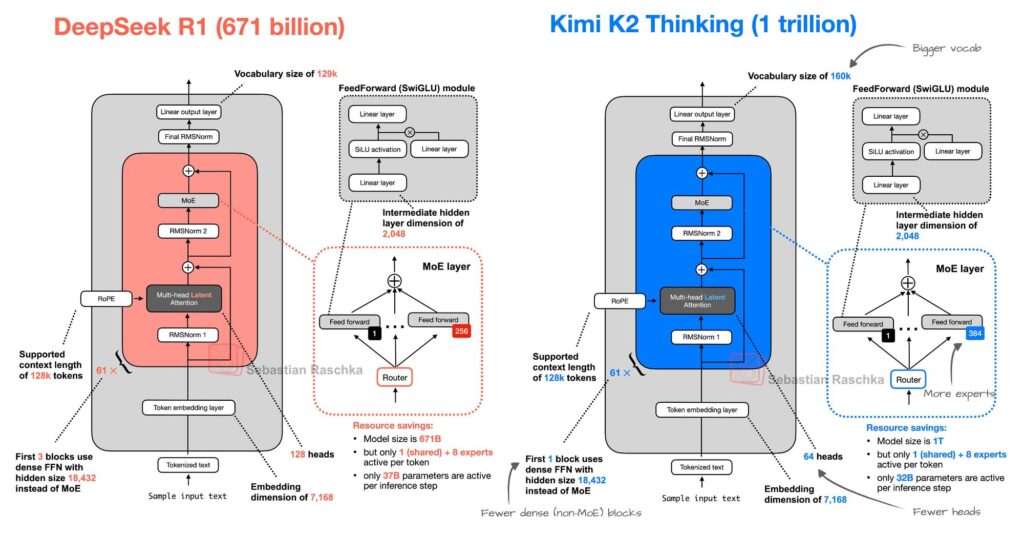
Generally speaking, a “thinking” model means an AI that doesn’t just respond, but reasons, plans, and executes tasks, often by using external tools, chaining steps, and adapting dynamically. The model family from Moonshot AI, called Kimi K2, is built on a Mixture-of-Experts (MoE) architecture: 1 trillion total parameters, with ~32 billion “active” parameters per inference.
“Kimi K2 Thinking” is the agentic reasoning extension, which means it is optimized for long-horizon reasoning (200-300 sequential tool calls, 1 trillion total parameters, with ~32 billion “active” parameters per inference. ), tool-use, planning, and deep workflows.
Being an entrepreneur working with AI, what jumps out is this, if you’re building a product that needs more than “chat”; if you need the model to act, not just talk, then “thinking” models like this mark a paradigm shift. For AI researchers, it means open-weight access to a frontier architecture. For product leaders, it means the stack you can build on changes.
Also read: AI Product Roadmap Planning, Execution, and Growth Strategy
What exactly is “Kimi K2 Thinking”?
Let’s dig into what makes this variant distinct:
It inherits the base K2 architecture: 1 T total parameters, 32 B activated parameters, MoE with ~384 experts selecting ~8 per token.
But for the “Thinking” variant, Moonshot emphasises long-horizon reasoning and structured tool orchestration: it claims ability to execute 200-300 sequential tool calls in a single session, making it more agentic than earlier chat-only LLMs.
It supports large context windows and integration with real‐world tools (browsers, external APIs, code execution).
The company positions it as open-source (or open-weight) and deployable for research, entrepreneurship and product teams, not locked behind proprietary APIs.
We are also considering using such open source AI models at our AI startup, Inventegy AI, especially, since we are launching RYZER AI, to help C-suite executives, Product Leaders, Marketing and Sales professionals to leverage AI capabilities and grow businesses altogether.

You can signup for the waitlist, while it is still open and get early access!
From a business and product lens, “Thinking” means: you can go beyond Q&A, into workflows, agents, autonomous modules. You now have access to a stack that reduces the “black-box” risk of proprietary models.
From an AI researcher’s point of view, you get a big platform to explore tool use, MoE routing, reasoning over long contexts.
Also read: AI Strategy for Product Leaders to Build Intelligent Products
How does Kimi K2 Thinking compare with other top models?
To decide if it’s the best model out there (or at least the best fit for many business/Product/AI research cases), we need comparison with other strong models: e.g., Claude Opus 4, OpenAI GPT‑4.1 (or ChatGPT variants), Gemini 2.5, Qwen 4 and Grok 4.
Architecture & positioning
- Kimi K2 Thinking: Built as a Mixture-of-Experts (MoE) model (≈ 1 trillion total parameters, ~32 billion activated per inference) designed specifically for agentic reasoning, long chains of tool calls and extended workflow contexts.
- Claude Opus 4 / Claude 4 family: Hybrid reasoning models from Anthropic, emphasising safe alignment, tool usage, reasoning and coding support.
- GPT-4.1: Dense model from OpenAI, strong generalist for reasoning/coding, widely used and robust.
- Gemini 2.5: Google/DeepMind’s large-context, multimodal capable model with very large token windows, emphasising document/multimedia tasks.
- Qwen 3: Alibaba’s emerging model, competitive in enterprise token-based pricing and strong in multilingual contexts.
- Grok 4: xAI’s model, strong in certain tool-augmented, real-time or reasoning-heavy benchmarks; emerging competitor.
- DeepSeek R1: Also a Mixture-of-Experts model, with ~671 billion total parameters and ~37 billion active per token. It supports large context windows (e.g., up to 128K tokens) and emphasizes cost-efficient reasoning workflows.
Also read: Applying Design Thinking to build innovative Cloud based AI Products
Kimi K2 Thinking – Performance Benchmarks
Here are some selected comparative data points (with caveats about different test sets / modes):
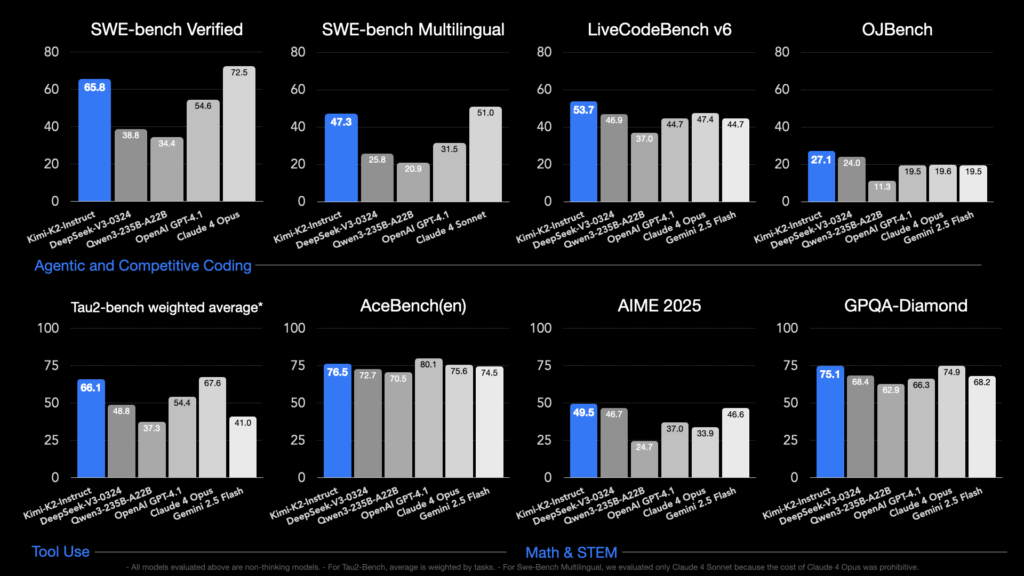
- Kimi K2 Thinking achieved ~44.9% on the “Humanity’s Last Exam (HLE)” benchmark (with tools) vs GPT variants at ~41.7%.
- Kimi K2 Thinking achieved ~60.2% on BrowseComp (agentic web-search + reasoning).
- Claude Opus 4 reportedly achieved ~72.5% on SWE-bench (software engineering) vs GPT-4.1 ~54.6%.
- Some independent reviews show Grok 4 leading in certain coding/logic benchmarking.
From this we can infer:
- Kimi K2 Thinking appears to match or exceed many of the leading proprietary models on agentic-tool reasoning and coding tasks while offering open-weight access.
- Gemini 2.5 excels more in large document/multimodal tasks with enormous context windows, rather than strictly reasoning/coding edge cases.
- Claude Opus 4 excels in coding + reasoning with enterprise safety orientation.
- Qwen 3 and Grok 4 show strong niche strengths (multilingual, real-time tool use) but may vary across tasks.
- GPT-4.1 remains a strong generalist but may be overtaken for highly agentic or tool-chain workflows by the newer “thinking” models.
Kimi K2 Thinking – Pricing / Cost Comparison
One of the most disruptive parts:
- Kimi K2 (commercial API) reported pricing: $0.15 per million input tokens, $2.50 per million output tokens.
| Usage Type | Price per 1 M input tokens | Price per 1 M output tokens |
|---|---|---|
| Kimi K2 Thinking (cache hits) | ~$0.15 | ~$2.50 |
| Kimi K2 Thinking (standard) | ~$0.60 | ~$2.50 |
Here’s a comparison table of the API pricing for several top models (per 1 million tokens) to help you benchmark your cost-model as a product leader and entrepreneur.
(Note: Prices are for published public-API or subscription tiers at the time of writing and may vary by region, plan, or caching discounts.)
| Model / Provider | Input Tokens Price | Output Tokens Price |
|---|---|---|
| Kimi K2 Thinking | ~$0.15 / 1 M | ~$2.50 / 1 M |
| Claude Opus 4 (Anthropic) | ~ $15.00 / 1 M | ~ $75.00 / 1 M |
| GPT‑4.1 (OpenAI) | ~ $2.00 / 1 M | ~ $8.00 / 1 M |
| Gemini 2.5 Pro (Google) | ~ $2.50 / 1 M | ~ $15.00 / 1 M |
| Qwen 3 (Alibaba) | ~ $0.20 – $1.60 / 1 M | ~ $0.60 – $4.80 / 1 M |
| Grok 4 (xAI) | ~$ $3.00 / 1 M | ~ $15.00 / 1 M |
Kimi K2 Thinking – Enterprise Production Usage
- Kimi K2 Thinking: Its biggest product appeal is that you get high reasoning + tool-use + open-weight deployment flexibility. For entrepreneurs/product teams this means less vendor lock-in and more customization.
- Claude Opus 4: Enterprise heavy, known for reliability, strong coding/agentic performance, but higher cost and closed weight.
- Gemini 2.5: If your use case involves massive context, rich multimodal (text+image+video) data, document analysis, Gemini may lead. But you might sacrifice some edge in pure reasoning agentic workflows.
- Qwen 3: Strong cost-/token-pricing edge especially in multilingual/enterprise Asian markets; competitive for regional product plays.
- Grok 4: Especially for workflows that require tool integration, real-time data, or “live” reasoning, Grok may win. But it may require specialized setup.
- GPT-4.1: Still a safe generalist, supported by large ecosystem and lots of integrations. If you simply need steady performance without pushing the frontier, it remains a choice.
| Model | Key Strengths | Notes / Trade-offs |
|---|---|---|
| Kimi K2 Thinking | High reasoning + tool-use + open-weight | Hosting/infrastructure still heavy; newer ecosystem |
| Claude Opus 4 | Strong coding + reasoning + enterprise safety | Closed weight; higher cost |
| GPT-4.1 | Broad ecosystem, reliable generalist | Might lag in highly agentic workflows |
| Gemini 2.5 | Large context, multimodal, document scale | Slightly lower reasoning edge in agentic tasks |
| Qwen 3 | Cost-token efficiency, multilingual, enterprise Asia focus | Less widely benchmarked globally |
| Grok 4 | Tool-integration, real-time reasoning, developer friend | Less mature ecosystem; may need specialized setup |
How Business Leaders, Entrepreneurs & AI Researchers can adopt Kimi K2 Thinking
Semantic keywords: enterprise AI adoption, product strategy AI, AI startup tool-use model
Here are actionable ways each stakeholder can leverage this new model.
Kimi K2 Thinking – For Entrepreneurs
- Autonomous workflow agents: Build applications where the model orchestrates tools, data fetches, system calls, rather than just chat.
- Vertical SaaS differentiation: Use the model’s capabilities to power domain-specific assistants (legal review, finance automation, supply-chain orchestration).
- Cost leverage: Because the token cost is low and you can self-host or deploy as you choose, you get product-led growth potential without high recurring API cost.
- Rapid prototyping: With open weights, you can fine-tune on your data, integrate with internal systems, iterate quickly.
Kimi K2 Thinking – For AI Researchers
- Agentic reasoning experiments: Study how multi-step tool-use emerges, explore chain-of-thought trajectories, explore how MoE routing influences emergent behaviour.
- Fine-tuning for domain tasks: Because of deployment flexibility, you can test custom datasets (e.g., scientific, legal, engineering) and analyse model behaviour in your niche.
- Benchmark extension: Use Kimi K2 Thinking to propose new benchmarks around autonomous agent tasks, long-horizon planning, tool orchestration.
Kimi K2 Thinking – For AI Strategists / Business Leadership
- Strategic stack decision: Position Kimi K2 Thinking as part of your tech architecture (e.g., reasoning layer), define how it interacts with data, tool infrastructure, human-in-loop.
- Cost and scalability modelling: Estimate token usage, deployment cost, latency, scale across use-cases. Because cost per token is low, you can plan large-scale automation.
- First-mover advantage: Use it now to build differentiated functionality ahead of competitors still locked into high-cost proprietary models.
Also read: Designing High-Performance Product Strategy: A Leader’s Perspective
Conclusion
In the journey as an entrepreneur, business leader and AI strategist, I see Kimi K2 Thinking as a meaningful inflection point in how we build AI-driven products, research new capabilities and orchestrate intelligent workflows. It doesn’t simply generate text, it thinks, acts and chains tools in a way that opens up new product paradigms.
While established models like GPT 4.1, Claude Opus 4, Gemini 2.5, Qwen 3 and Grok 4 remain powerful anchors in the AI ecosystem, Kimi K2 Thinking offers a fresh combination of agentic reasoning, tool-chain orchestration, open-weight flexibility and cost-efficiency. For many innovators, that makes it the “best model to build on” right now, not because it’s flawless, but because it shifts the playing field.
In short, Kimi K2 Thinking may not yet solve every problem out of the box, but for the ambitious AI-products of 2025–26, those that require reasoning, autonomy and scalability, it very well could be the pivotal model that unlocks new possibilities.



