

I was ruminating about somewhat mystifying future of Artificial Intelligence (AI) while riding train back to home from work, when all of a sudden, the idea of how Artificial Intelligence could also leverage Apache Hadoop technologies, realised the demand of Hadoop skills has declined dramatically. I myself have been working in big data technologies (check our guide on How to design the right Big Data Architecture) for many years and cannot forget the immense amount of time and energy it took to build such skills. Even all the big-threes i.e. Amazon Web Services, Google Cloud Platform and Azure offer their own managed services (EMR, DataProc and HDInsight) by running Hadoop on top of them to several enterprises. So seeing this big guy being collapsed seems to be a bad thing to experience. Well, then I started researching on that and found the trend of Google search has also declined terribly:
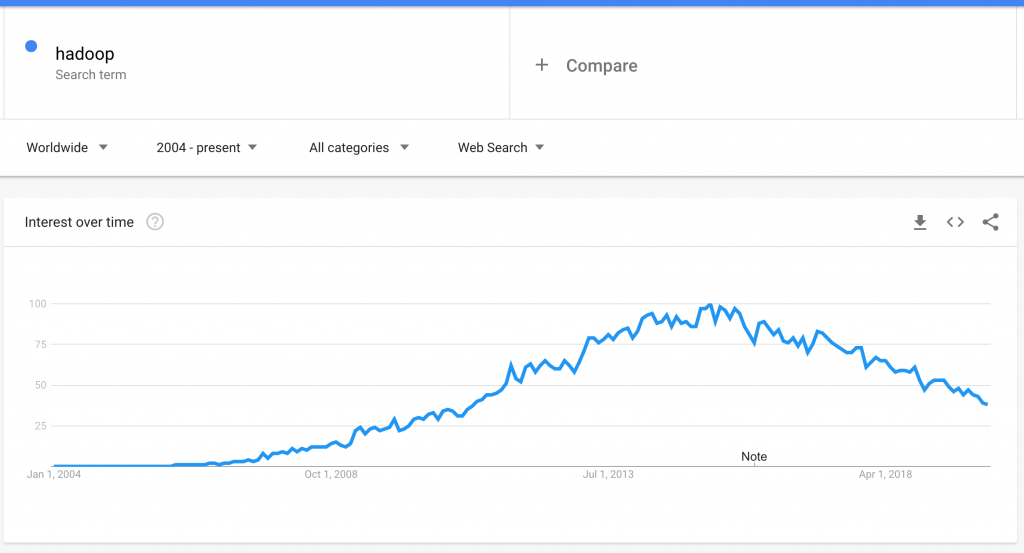
It is evident that Hadoop started picking up pace from 2008 and was on it’s peak by 2015. So, what has happened that would have caused it? Once, the king of Big Data world has slowly started disappearing lately… but why?
Following are my key take aways about the approximate obsoletion of this giant platform. But first, we need to grasp the basic understanding of what Hadoop really is!
What is Hadoop? And why it was needed?
With the advent of big data the need of sophisticated platforms has become paramount and extremely desirable. The single atomic reason was the legacy architecture of such platforms, wasn’t supporting the tremendous amount of calculations, aggregations, data processing, data governance and cleansing of historical data to obtain modern KPIs/analytics such as social media and brand awareness. Data Warehouse experts experienced substantial degree of hassle to deal with slow processing queries, data leakage, high latency, low availability and nearly no scalability. Organisations were capturing data from various sources and interested to see structured (SQL, CSV), semi-structured (JSON) and unstructured data (logs from clickstreams) at one single place, so they could perform analysis on them accumulatively.
Additionally, AI based applications such as training Machine Leanring models wasn’t really possible without that. It was too mundane and cumbersome for Data Scientist to run and their training model on a stand-alone machine. That would require insane amount of power, CPU, memory and hard disk resources to perform such a task.
So, Apache Hadoop – an open source Java based platform, was built to mainly deal with challenges mentioned above. One could perform tasks using MapReduce (data processing model) jobs and make data ready to load it into Hive (Hadoop based data warehouse uses SQL to query from HDFS), which then could be connected via a JDBC/ODBC connection and use KPIs to present them on dashboards or almost any available Business Intelligence tools (QlikView, Tableau, etc.). These data processing jobs run on the disk in the form of batches (also known as data spill on disk). It was also capable enough to plenty of other scenarios apart from this specific use case. Data Scientists are also taking benefit by training models in a much better fashion as they have a reach to all sets of data different sources at a single place – which is the soul of AI.
Architecture
Master-slave architectural pattern adapted to store data in a distributed environment. The architecture (read more at: Apache Hadoop Architecture ) is highly scalable, fault-tolerant and very little prone to failure or one may say strongly fail-safe. Which means after configuration, backups are always there in case of cluster failure. Commodity hardware are used to distribute bigger jobs into smaller ones. This distribution takes place on a multi-tier environment, called Cluster, to leverage the power of CPUs, memory and disk drives of every single node (computer) in that cluster.
Hmm.. so, if this was such an astounding silver-bullet to deal with enormous issues, why people and companies are getting off-the-hook? Here is why!
Slowly killing deadly reasons
Although, it was solving some challenges but has introduced other type of challenges, including:
Configuration: It would require immense amount of time to really erect a new custom cluster. There were vendors like Cloudera, who were helping out by providing help through documentation and other technical resources. Of course, this help cost a lot of money!
Maintenance: Once a cluster is running with many jobs to process data, it may lead to slow it down. Periodic cleaning was always needed. Adding and fixing new patches were always a painful task to perform.
Skills: Learning new skills are never easy, but learning Hadoop was even difficult thing. You may read a lot of documentation, but can never learn something until you practice it. And practicing Hadoop isn’t easy, since it requires huge amount of data and setting up a cluster to run tasks on top of it. Shortage of Hadoop skills was definitely one of the biggest part of it’s decline in data world.
Time consumption: Let’s be honest, it was designed to run batch jobs on a historical data. However, it is quite difficult to build a good understanding to authorities about why it takes a lot of time to process few terabytes of data. Specially, since realtime analytics have become paramount importance to almost all the industries, munching those KPI numbers need to be presented fast!
Lastly, I assume, these key challenges are very well addressed if a cloud based Hadoop cluster via managed services is selected as an option to run Big Data tasks. However, if Hadoop is chosen to be a tailored solution, it might be a good idea to use modern in-memory data processing engines such as Apache Spark or Storm. So, saying if Hadoop is completely dead? Perhaps not!



