In the fast-evolving world of AI, Elon Musk’s xAI brings Grok 4.1, that emerges not just as another language model, but as a thinker, a collaborator, and a creative partner. Imagine an AI that can reason through complex problems, understand subtle emotional cues, and craft narratives with both logic and imagination. Businesses, researchers, and strategists now have a tool that doesn’t simply respond, it engages, analyzes, and elevates human decision-making. This article takes you on a journey through Grok 4.1’s innovations, its performance benchmarks, pricing, and how its reasoning and emotional intelligence can transform the way organizations and creators interact with AI.
The Arrival of Human-Aligned Reasoning AI
Grok 4.1 represents a meaningful shift in the evolution of large language models (LLMs), combining deep reasoning, emotional intelligence, alignment safety, and enterprise utility in a way that previous generations only hinted at. It seems like this model is designed to think, interpret, empathize, adapt, analyze, and support both human creativity and decision-making at scale.
What I see sets Grok 4.1 apart is its dual-mode cognitive architecture, enabling it to switch between rapid conversational response and high-level reasoning, mirroring how humans adjust depth depending on context. For businesses, strategists, engineers, and AI researchers, this dual-mode capability opens a new world of operational flexibility, cognitive depth, and cost efficiency.
What is Grok 4.1?
According to their official announcement and the website, Grok 4.1 is xAI’s latest large language model built to excel at reasoning, factual consistency, emotional nuance, and agent-like task execution. It introduces a stronger safety framework, deeper alignment tuning, and significantly improved conversational stability.
Where past models were “smart,” Grok 4.1 is strategic.
Where past models were “accurate,” Grok 4.1 is self-corrective.
Where past models were “interactive,” Grok 4.1 is empathetically aware.
Its architecture and training methodology embody a synthesis of reinforcement learning, preference modeling, chain-of-thought refinement, and robust risk-mitigation layers.
We are also building a new AI product at our AI startup, Inventegy AI, and have been seeing a lot of interest lately, it’s RYZER AI, to help C-suite executives, Product Leaders, Marketing and Sales professionals to leverage AI capabilities and grow businesses altogether.

You can signup for the waitlist, while it is still open and get early access!
What Has Recently Changed in Grok?
The latest version of Grok builds on a rapid iteration cycle throughout early November. It underwent silent testing phases, calibration rounds, and real-world evaluations before reaching public release. During this period, the model showed measurable improvements in reasoning tasks, emotional comprehension, contextual depth, and factual precision. These upgrades elevated its ranking across industry-standard evaluations and user-preference testing.
What stands out most is not just the jump in benchmark scores but the consistency of its behavior. Grok 4.1 handles ambiguity with more stability, understands user intent more thoroughly, and responds with a coherent conversational style that feels more grounded and human, which is pretty nice, I’d say!
Here are the major updates introduced:
1. Major improvements in reasoning depth in Grok
Grok 4.1 significantly improves multi-step logical reasoning, making it ideal for analysis, planning, technical problem solving, and agentic workflows. This is especially beneficial for enterprise-grade decision systems and advanced research tasks.
2. A new emotional intelligence layer in Grok
The model can identify emotional cues and respond with human-like nuance. It understands tone, context, sentiment, and social dynamics more effectively, making it a powerful asset for customer support, coaching, HR, and public-facing applications.
3. Substantial reduction in hallucinations in Grok
Through improved factual-checking pathways and refined reward-model alignment, Grok 4.1 produces fewer invented facts, making it more reliable in serious domains like finance, legal, medicine, compliance, and research.
4. Better personality coherence and conversational flow
The model maintains narrative stability, consistent style, and aligns better with brand voice. Businesses can shape its persona more reliably without drift or inconsistency.
Also read: Anthropic Uncovers Vibe Hacking – First AI-Orchestrated Cyber Espionage Campaign
How Grok 4.1 Works – Mechanisms & Architecture
From a research and strategic standpoint, Grok 4.1 builds upon the architecture of Grok 4 but with refinements:
1. Dual-Mode Intelligence (Thinking vs. Non-Thinking)
Grok 4.1 features two operational modes: a high-speed mode for instant responses and a thinking mode that activates deeper analytical processes. In thinking mode, the model draws on structured internal reasoning paths, allowing it to break down problems, explore multiple angles, and generate higher-quality answers. This capability is particularly valuable in scenarios like planning, technical analysis, or multi-step logic tasks. Conversely, the non-thinking mode enables smooth, fast, conversational interactions ideal for large-scale customer-facing applications.
- Thinking Mode
- Uses internal reasoning tokens
- Produces structured, multi-step, chain-of-thought-level outputs
- Ideal for analysis, planning, logic-heavy tasks, agentic workflows
- This mode triggers structured reasoning sequences, allowing Grok to:
- Break down complex problems
- Explore alternatives
- Generate analytical insights
- Support multi-step agent tasks
- Improve reliability in high-stakes decision scenarios
- Think of it as the AI equivalent of “slow, deliberate thought
- Non-Thinking Mode
- Ultra-fast responses
- Minimal latency
- Best for conversational tasks, high-volume operations, customer-facing experiences
- Speed
- Latency reduction
- Low-cost operation
- Natural conversation flow
- It is ideal when volume, speed, and simplicity matter more than depth.
This duality allows organizations to optimize for cost, quality, and speed simultaneously.
Also read: Kimi K2 Thinking: A New Frontier for Agentic AI, Benchmarks and Pricing
2. Reinforcement Learning With Advanced Reward Models
It looks like the model benefits from reinforcement learning informed by a wide range of human feedback signals. These reward models evaluate not only correctness but also conversational tone, empathy, clarity, consistency, and safety. The system continuously refines its decisions by comparing its outputs against human-preferred patterns. This produces responses that feel more intentional, more aligned with human communication norms, and significantly more stable under pressure.
Grok 4.1 uses a refined reinforcement learning pipeline that incorporates:
- Agentic reward models for evaluating decision quality
- Human-preference-based reward shaping
- Reinforcement learning signals for personality coherence
- Alignment-focused behavior scoring (style, tone, empathy)
- Error-reduction rewards targeting hallucination minimization
As an AI strategist, this is notable because xAI is converging on a hybrid alignment method that blends policy shaping, preference modeling, and safety-engineering feedback loops.
3. Emotional Intelligence Enhancements
Grok 4.1’s emotional intelligence enhancements help it recognize tone, understand subtle emotional cues, and respond with improved warmth and contextual sensitivity. Instead of delivering flat or overly mechanical replies, it adapts its style to the situation- supportive when needed, direct for analytical tasks, and neutral in high-stakes decision contexts. This makes it uniquely capable of bridging human conversations with machine logic.
The model shows stronger performance in interpreting human sentiment, adapting tone, and maintaining conversational empathy. This is a major differentiator from traditional reasoning models that tend to be rigid or overly formal.
Key emotional-intelligence improvements include:
- Better recognition of nuance and implied meaning
- More supportive and contextually aware replies
- Better conflict-diffusion language patterns
- Reduced aggressive/overconfident failure modes
4. Safety, Alignment & Risk Management
A renewed focus on risk management led to integrated behavioral checks, misinformation filters, and adversarial detection. Grok 4.1 is designed to avoid speculative or fabricated answers and to transparently navigate uncertain situations. This careful balancing of confidence, humility, and clarity dramatically reduces harmful or misleading outputs while maintaining its reasoning strength.
Grok 4.1 introduces a more mature alignment framework:
- Multi-layer safety filters
- Risk assessments for dual-use behaviors
- Expanded checks for misuse and adversarial prompting
- Behaviour stability evaluations across large user samples
- A reduction in problematic or harmful output patterns
For organizations deploying Grok at scale, this means higher reliability across sensitive or regulated domains.
Also read: AI Strategy for Product Leaders to Build Intelligent Products
Grok’s Advanced Reinforcement Learning (RLHF, RLAIF, and Reward Architectures)
From a research and engineering standpoint, I think this is one of Grok 4.1’s greatest strengths. New reward models evaluate outputs based on:
- Correctness
- Style alignment
- Personality coherence
- Risk level
- Emotional semantics
- User-centered communication patterns
These continuous feedback loops help the model balance logic with empathy and safety, something only a handful of modern LLMs can achieve reliably.
Emotionally Intelligent Language Modeling
Grok 4.1 incorporates refined emotional intelligence through:
- Enhanced tone detection
- Sensitivity to stress, frustration, or doubt in user messages
- Adaptive wording for different levels of formality or vulnerability
- Better conflict-resolution language patterns
This is a critical differentiator for businesses that rely on AI-human collaboration.
Safety and Hallucination Reduction Framework
The updated safety system conducts multi-step evaluations to minimize:
- Incorrect or fabricated information
- Unsafe recommendations
- Harmful or biased responses
- Overconfident false assertions
This yields a model that is far more controlled, self-aware, and trustworthy for enterprise deployment.
Also read: Applying Design Thinking to build innovative Cloud based AI Products
Grok 4.1 Performance Benchmarks and Real-World Indicators
Grok 4.1 exhibits a notable rise in performance across reasoning, emotional capability, and real-world conversation quality. The model’s thinking mode ranks among the strongest on public leaderboards, surpassing many high-end models in logic-heavy tasks. Its emotional intelligence indicators also show meaningful improvement, demonstrating an ability to maintain empathetic, coherent dialogue even in nuanced, sensitive scenarios.
Perhaps most importantly, blind user studies show a strong preference for Grok 4.1’s outputs. This implies that the improvements translate beyond technical metrics – they are felt directly in the lived experience of interacting with the model, which is essential for enterprise adoption.
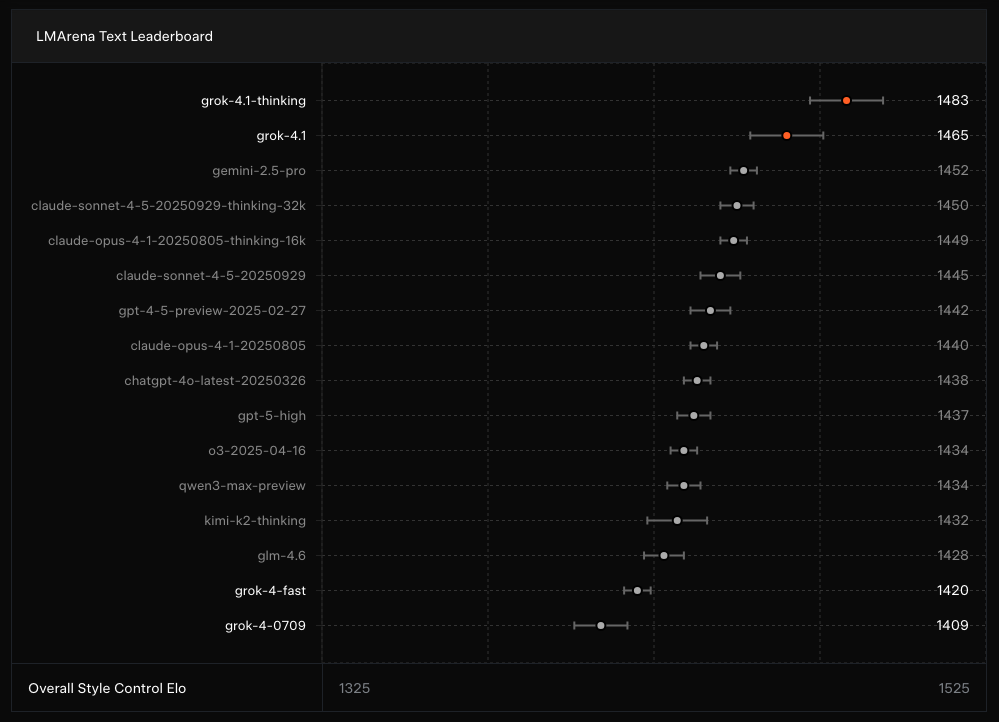
Creative Writing Benchmark
Grok 4.1 shows strong performance across creative writing benchmarks, scoring highly on:
- Narrative coherence – maintaining consistent characters, tone, and story arcs
- Imagery and metaphor quality – using richer, more vivid descriptions
- Emotional layering – adding depth and complexity to character emotions
- Stylistic adaptability – shifting effortlessly between literary styles, genres, and voices
- Story originality – producing narratives with unique plot structures and inventive concepts
In creative writing evaluations, Grok 4.1 demonstrates a noticeable leap in:
- Dialogue realism
- Scene setting
- Humor accuracy
- Tone matching for branding or authorship emulation
This positions Grok 4.1 as a compelling tool for marketing teams, storytellers, content creators, and entertainment workflows seeking AI-assisted narrative generation with emotional and stylistic depth.
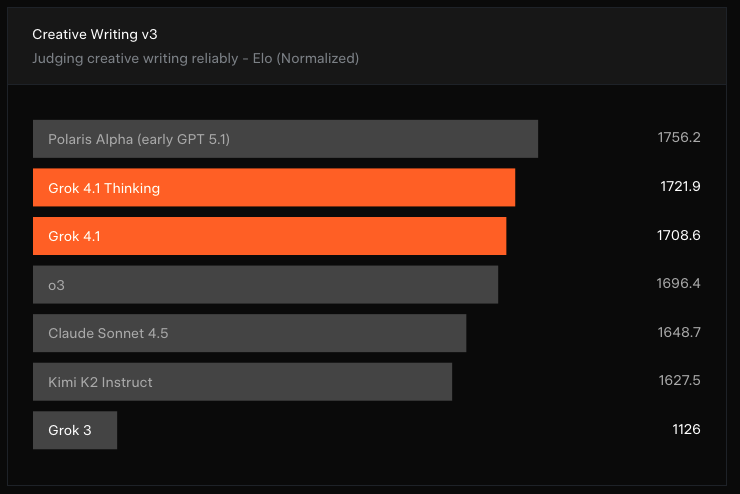
Emotional Intelligence Metrics
The model demonstrates noticeable gains in tone adaptation and empathetic understanding. This places it above many models that are optimized purely for reasoning but fall short in human-like interaction.
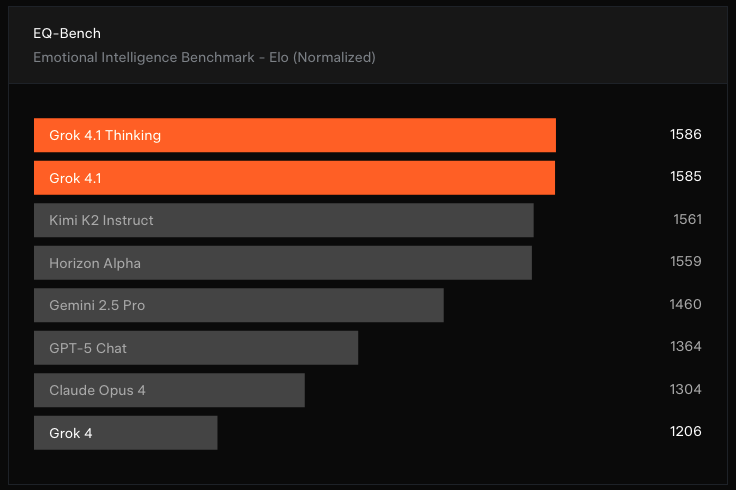
Hallucination Reduction
Grok 4.1 delivers a significantly more reliable output stream by reducing fabricated answers, reinforcing factual verification, and enhancing internal reasoning stability.
- More stable reasoning core that minimizes ungrounded or speculative statements.
- Redesigned inference pathways that sharply reduce confident but incorrect answers.
- Stronger factual verification through improved internal cross-referencing and logic checks.
- Greater long-form consistency, preserving details and coherence across extended conversations.
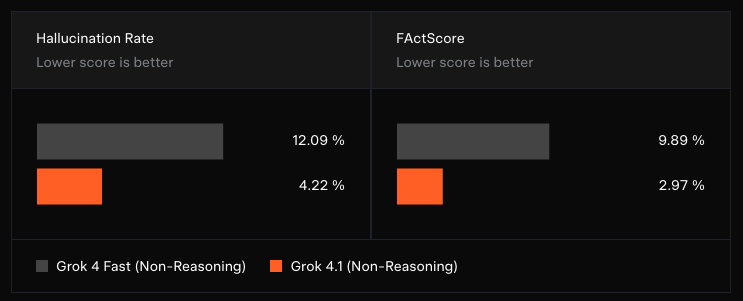
These benchmarks are also available at Grok’s official website and announcement
Grok 4.1 Pricing
| Pricing Tier | Monthly Cost (USD) | What You Get / Notes |
|---|---|---|
| SuperGrok (Standard) | ~$30 / month | Access to Grok 4 standard via web or app. |
| SuperGrok Heavy | ~$300 / month | Grok 4 Heavy (multi-agent reasoning), higher rate limits. |
| API – Input Tokens | $3.00 per 1 M tokens | For developers, input tokens cost $3 / million. |
| API – Cached Input Tokens | $0.75 per 1 M tokens | Cheaper when reusing recent prompts. |
| API – Output Tokens | $15.00 per 1 M tokens | Completion / response token cost. |
Grok 4.1 vs GPT 5.1 vs Claude Sonnet vs Gemini (Nov 2025)
| Provider & flagship model | Input ($/1M tok) | Output ($/1M tok) | Typical 1-in/5-out chat ($/1M tok) | Notes |
|---|---|---|---|---|
| xAI Grok 4 | $3.00 | $15.00 | $18.00 | 256 k ctx; reasoning-only mode |
| OpenAI GPT-5 | $1.25 | $10.00 | $11.25 | 128 k ctx; 90 % prompt-cache discount |
| Anthropic Claude Sonnet 4.5 | $3.00 | $15.00 | $18.00 | 1 M ctx; doubles if >200 k tokens |
| Anthropic Claude Opus 4.1 | $15.00 | $75.00 | $90.00 | 200 k ctx; premium reasoning |
| Google Gemini 2.5 Pro | $1.25 | $10.00 | $11.25 | 1 M ctx; best \$/perf on many benchmarks |
- Cheapest flagship: GPT-5 and Gemini 2.5 Pro tie at ~$11 per million “typical” tokens.
- Mid-field: Grok 4 and Claude Sonnet 4.5 cost ~60 % more ($18).
- Premium tier: Claude Opus 4.1 is 5× pricier than the leaders but still tops coding/reasoning leaderboards.
- Context kings: Gemini 2.5 Pro and Claude Sonnet 4.5 give 1 M-token windows—whole repos or long docs in one pass.
You can find more about the model comparision at: Artificial Analysis
Implications for Business Leaders, AI AI Strategists & AI Researchers
From my vantage point as an AI strategist and researcher, Grok 4.1 is significant in several ways. Here’s how different stakeholders can leverage it:
For Business Leaders
- Customer Experience & Support: Grok 4.1’s improved emotional intelligence means it can be more effective in customer service, offering empathetic, human-like conversation – not just factual replies.
- Brand Voice & Storytelling: With stronger creativity in writing, Grok 4.1 can help generate marketing copy, social media content, or even campaign narratives that better align with brand personality.
- Cost-Efficiency: The non-thinking mode offers fast, lower-cost interactions that are suitable for high-throughput scenarios, while the thinking mode can be reserved for more complex tasks.
For AI Strategists & Product Leaders
- Agentic Applications: The reasoning mode enables more advanced agent-like behavior (tool use, planning), meaning you can build more sophisticated AI workflows
- Safety & Alignment Design: The fact that xAI uses agentic reward models for alignment suggests a mature approach – strategists might study this as a benchmark for building aligned, human-preference-aware systems.
- Hybrid Model Deployment: You can architect systems that dynamically switch between thinking and non-thinking modes depending on latency, cost, and quality needs.
For AI Researchers & Thought Leaders
- Empathy in LLMs: Grok 4.1 is a case study in improving emotional reasoning; researchers can analyze how reward models influenced empathy, coherence, and style.
- Trade-Offs in Reasoning: The dual-mode design (reasoning vs. non-reasoning) is a rich ground for exploring cost vs. depth trade-offs.
- Safety Evaluations: With the published model card, there’s transparency around risk assessments: researchers can critique or extend these evaluations in areas like misuse, dual-use, or shutdown resistance.
Conclusion
Grok 4.1 stands at the intersection of technical sophistication, human-level emotional awareness, and enterprise-readiness. As a reasoning model, it pushes the frontier of what structured cognitive processing in AI can achieve. As a conversational model, it deepens the emotional and contextual connection between humans and machines.
It sure does seem like, is not merely a “better chatbot.” It is a blueprint for a new class of AI systems that :
- Think deeply
- Communicate authentically
- Adapt intelligently
- Operate safely
- Collaborate meaningfully
For executives, engineers, researchers, strategists, and thinkers, Grok 4.1 represents a powerful step toward a future where AI does not just compute but understands, reasons, and aligns with human purpose.