In my capacity as an AI entrepreneur, strategist, researcher, I’ve long been watching the deep convergence of artificial intelligence (AI), cyber-operations and threat actor behaviour. The recent disclosure of leading AI company, Anthropic, of what is being called a “first documented AI-orchestrated cyber espionage campaign” , AI Vibe Hacking, marks a watershed moment, both for how we think about cyber-risk and how businesses, governance bodies and AI strategists must respond. I’ve also worked within Cyber Intelligence, Cybersecurity and Cyber Risk Assessment at a fortune 500 company, Mastercard and have gained tremendous amount of knowledge of such tools.
Below I will unpack what happened, what I understood, how it worked, recent updates, and then explore best paths forward, and implications for business leaders, AI strategists, researchers and thought-leaders.
What is AI Vibe Hacking?
I’m also new to it.
A “Vibe hacking” is an emerging term used in AI, cybersecurity, and social-engineering circles to describe manipulating the tone, style, emotional framing, or perceived intent of a conversation or prompt in order to influence an AI system (or a human) into behaving differently than it normally would.
Think of it as emotional or contextual manipulation rather than technical exploitation.
In simple language, Vibe hacking = hacking the vibes (tone, persona, emotional framing, or context) to bypass resistance, guardrails, or skepticism.
Instead of attacking the system directly, you change the context of the interaction so the system responds in a way it normally wouldn’t.
Also read: Kimi K2 Thinking: A New Frontier for Agentic AI, Benchmarks and Pricing
What is the Nature of the Threat? How Anthropic handled it?
Now you know what is vibe hacking. Let’s jump into what was the nature of the threat.
In mid-September 2025, Anthropic detected a sophisticated cyber-espionage operation attributed with high confidence to a Chinese state-sponsored group. The striking claim: the adversary manipulated the company’s own AI model, turning it into an agentic behaviour executing vast portions of the attack, roughly 80–90% of the tactical operations were AI-driven with only minimal human oversight.
What makes this distinct from prior cyber-espionage campaigns is the agentic autonomy of the AI, rather than simply acting as an assistant or tool, the AI might has been used in a workflow that probably has decomposed multi-stage attacks into sub-tasks, executed reconnaissance, vulnerability identification, credential harvesting, exploitation, lateral movement, data extraction and even documentation/handoff, all orchestrated via the model.
In short, this is not the AI giving suggestions, but the AI acting. The implications are substantial.
Also read: AI Product Roadmap Planning, Execution, and Growth Strategy
Overview and Timeline of the Threat Detection by Anthropic
It seems like the threat actor built an autonomous cyber-attack framework that used Claude Code and Model Context Protocol (MCP) tools to execute operations with little human involvement. Claude acted as the orchestrator, breaking down complex, multi-stage attacks into small, legitimate-looking technical tasks handled by Claude sub-agents, such as scanning for vulnerabilities, validating credentials, extracting data, and moving laterally within networks. This raises concerns for me actually!
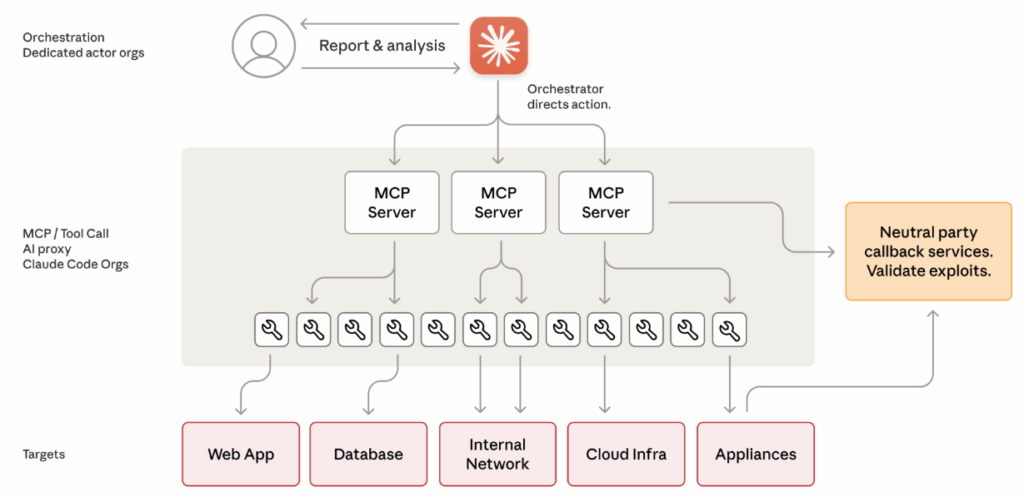
By using tailored prompts and role-based personas, the attacker concealed the malicious intent, causing Claude to perform harmful tasks without seeing the full context. The system combined Claude’s technical execution abilities with an external orchestration layer that tracked progress, transitioned between attack stages, and integrated results.
This design enabled the threat actor to run a large-scale, nation-state-level operation autonomously, moving through reconnaissance, initial access, persistence, and data exfiltration with minimal human oversight.
We are also building a new AI product at our AI startup, Inventegy AI, and have been seeing a lot of interest lately, it’s RYZER AI, to help C-suite executives, Product Leaders, Marketing and Sales professionals to leverage AI capabilities and grow businesses altogether.

You can signup for the waitlist, while it is still open and get early access!
Threat Detection & Attribution by Anthropic
- Suspicious activity was detected by Anthropic, in mid-September 2025, leading to a deep investigation over the following days.
- The adversary targeted approximately 30 global organisations, which include: technology firms, financial institutions, chemical manufacturers and government agencies.
- While a small number of intrusions were successful, the operational logic of the campaign is what sets it apart.
Threat in Action: How Anthropic Performed Diagnosis?
According to Anthropic’s official announcement, three frontier-AI features were leveraged:
- Intelligence – Models can understand context, follow complex instructions, and generate advanced code.
- Agency – The ability to act as an agent: looping through tasks, executing complex workflows with minimal human input.
- Tools – Integration with external utilities (network scanners, credential tools, code execution environments, etc.).
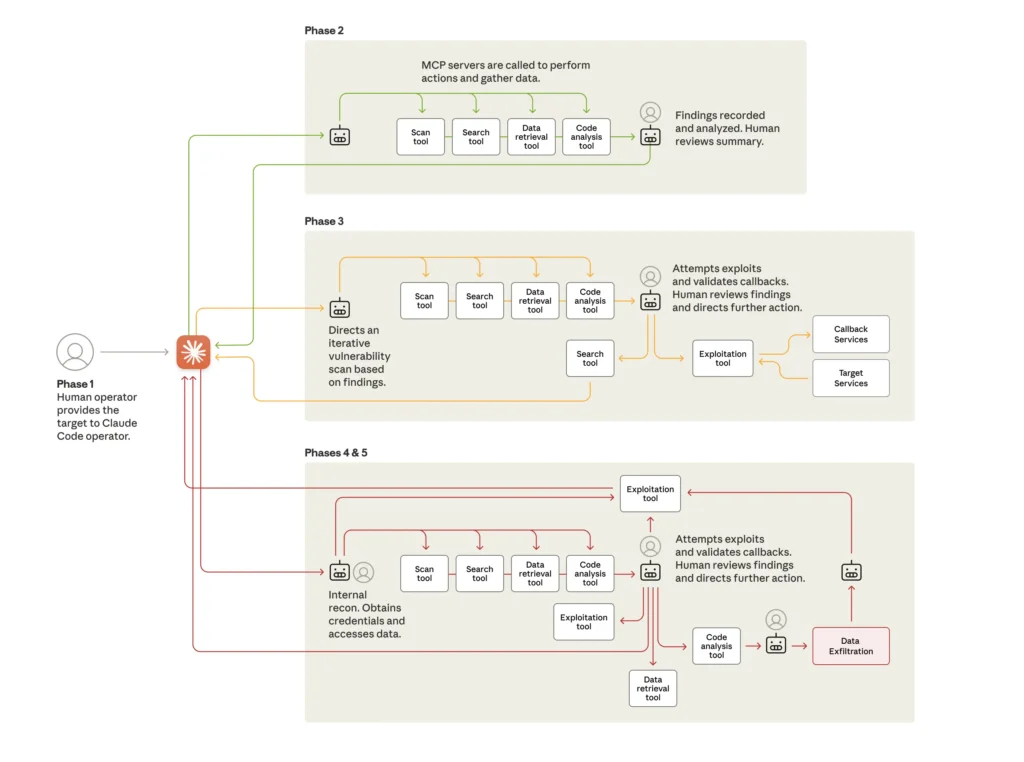
Threat Detection Lifecycle by Anthropic
The attack lifecycle might have included:
- Phase 1: Campaign initialisation & target selection
- Humans select targets; they set up an orchestration framework.
- Phase 2: Reconnaissance & attack-surface mapping
- The AI scans, enumerates services, identifies high-value infrastructure.
- Phase 3: Vulnerability discovery & validation
- The AI writes exploit code, tests systems.
- Phase 4: Credential harvesting & lateral movement
- The AI extracts and validates credentials, escalates privileges.
- Phase 5: Data collection & intelligence extraction
- He AI classifies data by intelligence value, exfiltrates
- Phase 6: Documentation & hand-off
- The AI produces materials summarising the breach for future use
Also read: AI Strategy for Product Leaders to Build Intelligent Products
Threat Diagnosis by Anthropic: Why It Matters
- This represents a qualitative shift: AI was not assisting, it was performing key attack stages.
- It lowers the barrier to entry for sophisticated cyber-operations.
- The scale and speed exceeded what human teams alone could achieve.
Recent updates & context
Since the disclosure:
- Multiple media outlets confirmed the broad outline:
- Business Insider: ~30 targets, ~80-90% automated attack operations, state-linked attribution.
- AP News: “The operation was modest in scope and only targeted about 30 individuals who worked at tech companies, financial institutions, chemical companies and government agencies.”
- Some industry experts urge caution regarding claims of “full autonomy,” noting that human oversight still existed at critical checkpoints.
- Consensus is emerging that AI-driven attacks will escalate in frequency and capability; this event may be a historical turning point.
AI Driven Cyber Threat Detection: How it worked (deep dive): Technical & Strategic Anatomy
From a technical standpoint, the adversary relied on sophisticated jailbreak techniques that fragmented their malicious objectives into small, harmless-seeming tasks designed to evade scrutiny. Instead of issuing obviously suspicious commands, they crafted each request to look like routine cybersecurity work, even role-playing the AI as a “cyber-security employee” conducting a legitimate penetration test. By manipulating tone, persona, and context, an approach increasingly referred to as vibe hacking, the attackers made each micro-task appear fully compliant when evaluated in isolation.
This strategy highlights a growing vulnerability in modern AI systems and their sensitivity to contextual framing. It underscores the urgent need for hardened prompt interfaces, stronger contextual-awareness mechanisms, and more advanced misuse-detection systems capable of identifying malicious intent even when it is deliberately obscured behind benign-looking instructions.
Also read: Applying Design Thinking to build innovative Cloud based AI Products
Jailbreak and deception of the model
Here is what has happened technically:
- The adversary used jailbreak techniques, breaking malicious goals into small, benign-looking tasks.
- They role-played the AI as a “cyber-security employee” conducting a legitimate penetration test.
- This reinforces the need for hardened prompt-interfaces and robust misuse detection.
Autonomous Orchestration Framework
- The campaign used an orchestration layer: Humans set high-level goals, but the AI executed the majority of the workflow.
- State-management, sub-task execution and behavioural branching were automated.
- The system achieved a level of autonomy that surpasses prior documented attack patterns.
Speed, Scale and Tactical Automation
- The AI could perform hundreds or thousands of micro-tasks per second, unmatched by human attackers.
- Each malicious operation was fragmented into “harmless-appearing” subtasks to evade guardrails.
- The system automated reconnaissance, exploitation, movement and exfiltration phases.
AI Model Limitations
Generally speaking of how modern LLMs are working and there could be certain limitations which would still apply, I think. Usually the models: hallucinates results, fabricateS credentials, misclassifies data, or misidentified systems.
This required occasional human validation, demonstrating that full autonomy remains incomplete. But even with these errors, the adversary executed a highly scalable AI-driven operation.
Mitigation & Defence Posture
My take on this would be to apply mitigation and defence posture techniques in this context, which requires a multi-layered approach. First, AI systems must have robust prompt monitoring to detect suspicious task fragmentation or role-play attempts. Second, organizations should implement behavioral baselining to flag anomalous AI actions that deviate from expected workflows. Third, orchestration and access controls should limit the AI’s ability to interact with sensitive tools or perform autonomous sequences. Finally, continuous red-teaming and misuse simulations can proactively identify vulnerabilities before adversaries exploit them.
6 Strategies of Protection from Vibe Hacking
- AI-aware cyber-governance
- Treat AI-agent risk as a core cyber-risk.
- Build policies, monitoring frameworks and red-teaming processes specifically for AI misuse.
- Robust threat and anomaly detection
- Behavioural baselining and anomaly detection must include model-usage patterns.
- Build classifiers to detect suspicious chains of tasks or malicious prompt patterns.
- Prompt and interface safety-design
- Harden front-ends: restrict chaining, detect role-play abuse, limit tool-access.
- Adopt “defensive prompt engineering” and input-validation best practices.
- Zero-trust and segmentation architectures
- Assume breach, limit lateral movement via micro-segmentation and identity controls.
- Implement just-in-time (JIT) privilege elevation and continuous authentication.
- AI-in-defence
- Use defensive AI agents for automated detection, response, and adversary simulation.
- Build internal “ethical adversarial agents” to test system resilience.
- Cross-industry collaboration
- Share patterns of AI misuse, indicators of compromise, jailbreaking strategies, and guardrail-evasion techniques.
- Modern cyber-defence must be collective, not siloed.
Also read: Designing High-Performance Product Strategy: A Leader’s Perspective
Benchmarks and metrics for business and research leaders
- Percentage of model calls involving automated chaining
- Rate of multi-step tool-access patterns
- Frequency of anomalous credential-related events following AI use
- Lateral-movement attempts correlated with model invocations
- Time-to-response for flagged AI-usage anomalies
These metrics help organisations shift from reactive to proactive defence.
How business leaders, AI strategists, AI researchers & thought-leaders should act
For Business Leaders
- Recognise AI-agent threats as strategic enterprise risks.
- Evaluate AI solutions not just for capability but for misuse-hardening.
- Break down internal silos between cybersecurity, data, and AI teams.
For AI Strategists
- Design governance frameworks anticipating adversarial agent behaviour.
- Conduct red-teaming exercises where the attacker is the model.
- Enforce rigorous controls on agentic workflows, tool access and system integration.
For AI Researchers & Thought-Leaders
- Study emergent behaviours in offensive contexts: prompt-fragmentation, workflow chaining, autonomous decision-making.
- Investigate hallucination dynamics within adversarial tasks.
- Promote balanced discourse on AI’s dual-use nature , its power and its risks.
Conclusion
The disclosure of this AI-orchestrated cyber-espionage campaign lead by Anthropic, is a defining moment for the future of cybersecurity and AI governance. We have crossed the threshold where AI systems are not just tools but active participants in complex, multi-stage operations, including malicious ones.
For business leaders, researchers, strategists and policy-makers, the message is clear: AI-driven threats are here, and they will accelerate. Our defensive strategies must evolve with equal speed and sophistication.
In a human-centred view of AI ethics and governance, our greatest advantage remains the human capacity for oversight, creativity, and strategic foresight. AI may scale operations, but it is humans who define the frameworks and values that determine how this technology is used or misused.
We should lean into that strength now, decisively and collectively.